Advertisement
The available tools have always shaped the way we work with data. From the early days of local databases to modern cloud systems, each new platform has added a layer of speed, convenience, or flexibility. With Xet landing on the Hub, developers and data teams have something new that’s changing how they think about storage, collaboration, and code integration. This move brings a storage-first mindset into platforms where code is traditionally king. For those dealing with large-scale data or complex workflows, it could be a quiet shift with a big impact.
Xet is built around a straightforward idea: merge large data storage with the version control model developers already use. Git has long been the go-to tool for versioning code but doesn't handle large files or datasets well. That's where Xet comes in. Instead of forcing a workaround, Xet brings Git-like performance and commands to repositories that include datasets, models, and other heavyweight assets.
The underlying difference lies in how it stores and retrieves data. It uses a virtual file system that allows users to clone, pull, and interact with large files as if they were standard Git objects. But under the hood, it handles things differently. Files aren't duplicated each time there's a new commit. They're broken into chunks, deduplicated, and stored in a way that makes access fast and storage efficient.
Xet being on the Hub now means it's more accessible than ever. The Hub, which typically hosts code and models, also offers seamless integration with data versioning tools like Xet. This means researchers, engineers, and analysts can manage their models and training data side-by-side with their code, with full version history, collaboration features, and reproducibility baked in.
This isn't just about convenience; it's about alignment. In most machine learning workflows, code lives in GitHub or GitLab, while datasets sit in buckets on S3 or elsewhere. This separation causes delays, breaks reproducibility, and makes onboarding difficult. You can version your code easily, but doing the same with datasets often requires many scripts, manual syncing, or clunky metadata management.

With Xet on the Hub, that friction starts to disappear. A data scientist can commit a dataset alongside a training script and share it with a collaborator who clones the repo and gets everything – no need to download the data separately. The version history covers both code and data, so it’s easier to roll back, compare versions, or reproduce a result exactly.
It's also helpful for team environments where roles are mixed. Engineers may be refining deployment code, while analysts fine-tun data filters and researchers adjust model parameters. Tracking all these changes in one place cuts back on miscommunication and saves time. Each push to the repo is a full snapshot of the entire environment—not just the logic but the data it operates on.
From a tooling perspective, integration with the Hub means smoother automation, too. Many teams already rely on CI/CD pipelines that watch for updates to a GitHub repository. If that same repository includes versioned data and models, thanks to Xet, the pipeline can act on those changes directly. This adds speed and trust to production workflows.
Xet won't be for everyone, at least not right away. Teams should still think through questions before switching over. For example, how sensitive is the data? While Xet supports private repositories and access controls, some organizations have compliance needs beyond simple privacy.
Then there’s the learning curve. Although Xet uses familiar Git-like commands, there are still differences that new users have to get used to. Chunked storage, virtual filesystems, and data caching may not be familiar territory for teams used to S3 or GCS. That said, documentation is growing, and the core concepts are getting easier to grasp with each release.
Another factor is storage cost and performance. While deduplication and efficient storage are part of the appeal, teams must consider total file size, frequency of changes, and access patterns. A more traditional object store might still be the better fit for workloads with constant heavy read/write cycles on huge datasets
.
However, for most developers working with medium to large datasets in collaborative environments, the upsides of Xet on the Hub outweigh the trade-offs. It reduces context-switching, tightens version control, and brings data closer to where code already lives.
With Xet now available on the Hub, the path to better collaboration in data-driven projects is clearer. For developers who've long wanted data versioning that doesn't feel bolted on or clunky, this might be the moment things begin to shift.

It removes a longstanding boundary between code and data by allowing both to live, evolve, and be shared in the same environment. It aligns with how people already work rather than asking them to reinvent workflows around new tools. That quiet fit—familiar commands, familiar repo structure, but new capabilities—makes it a promising option for teams that need to stay fast and organized.
Whether working on machine learning models, analytics pipelines, or complex data transformation code, having Xet on the Hub simplifies collaboration. It's not about changing everything; it's about making the things you're already doing a little easier to manage and a lot easier to share.
Xet arriving on the Hub isn’t a flashy release, but it marks a turning point for how teams manage and share data. It blends into existing workflows without demanding a full rebuild of your toolchain, and that's where its strength lies. Putting data versioning in the same space as code and models helps teams stay aligned, reduce errors, and move faster. Whether you’re part of a small team experimenting with new models or part of a larger organization trying to streamline collaboration, this kind of setup offers a way forward that’s simple, efficient, and ready to scale with your work.
Advertisement

How PaliGemma 2, Google's latest innovation in vision language models, is transforming AI by combining image understanding with natural language in an open and efficient framework

What is Auto-GPT and how is it different from ChatGPT? Learn how Auto-GPT works, what sets it apart, and why it matters for the future of AI automation

How the Open Leaderboard for Hebrew LLMs is transforming the evaluation of Hebrew language models with open benchmarks, real-world tasks, and transparent metrics

How the apt-get command in Linux works with real examples. This guide covers syntax, common commands, and best practices using the Linux package manager

Ready to run powerful AI models locally while ensuring safety and transparency? Discover Gemma 2 2B’s efficient architecture, ShieldGemma’s moderation capabilities, and Gemma Scope’s interpretability tools

Anthropic secures $3.5 billion in funding to compete in AI with Claude, challenging OpenAI and Google in enterprise AI

Fond out the top AI tools for content creators in 2025 that streamline writing, editing, video production, and SEO. See which tools actually help improve your creative flow without overcomplicating the process

Learn the regulatory impact of Google and Meta antitrust lawsuits and what it means for the future of tech and innovation.

Need to save Python objects between runs? Learn how the pickle module serializes and restores data—ideal for caching, model storage, or session persistence in Python-only projects

How to use the ternary operator in Python with 10 practical examples. Improve your code with clean, one-line Python conditional expressions that are simple and effective

How AutoGPT is being used in 2025 to automate tasks across support, coding, content, finance, and more. These top use cases show real results, not hype
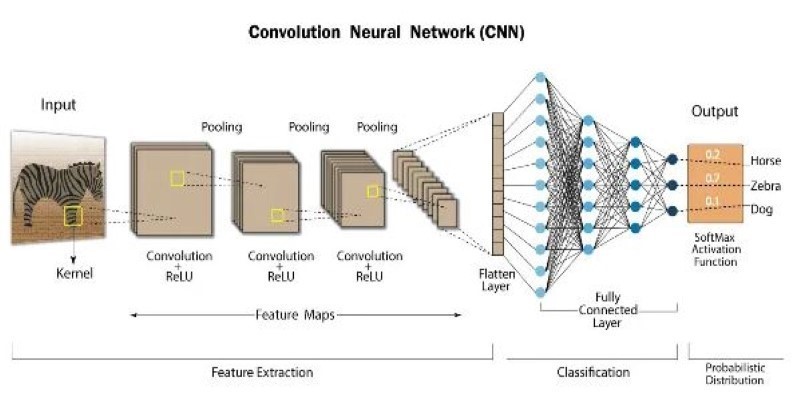
How atrous convolution improves CNNs by expanding the receptive field without losing resolution. Ideal for tasks like semantic segmentation and medical imaging