Advertisement
Convolutional neural networks (CNNs) are the standard tool for working with image data. They're built to identify patterns like edges, shapes, and objects. But when tasks require more detailed predictions—like classifying each pixel in an image—standard convolutions can't always keep up. They often shrink the image too much and miss small features.
Atrous convolution, also called dilated convolution, helps fix that. It increases a model’s field of view without increasing the number of weights or reducing the input resolution. This is especially useful for tasks like semantic segmentation, where both precision and context matter.
Regular convolution layers use small filters that move over the image, detecting local patterns. As layers stack up, pooling or strides shrink the image. This is good for classification tasks but not ideal when output needs to match input size—like labeling each pixel in an image.
Imagine segmenting road signs, lane markings, and pedestrians in a photo. Some features might only span a few pixels, and downsampling can erase these details. One might use larger filters or deeper models to avoid this, but that increases complexity. You trade off between a wide view and detail.
Atrous convolution provides a workaround. Instead of growing the kernel or adding layers, it stretches the filter across the input using gaps between weights. These gaps let the network see more of the input while keeping the resolution intact and parameters constant. It's a smart way to balance context and detail.
Atrous convolution modifies standard convolution by introducing a dilation rate. This rate decides how far apart the filter elements are spaced. A rate of 1 is the usual convolution. A rate of 2 skips one pixel between weights. A 3x3 filter with rate 2 covers a 5x5 area on the input without using more parameters.
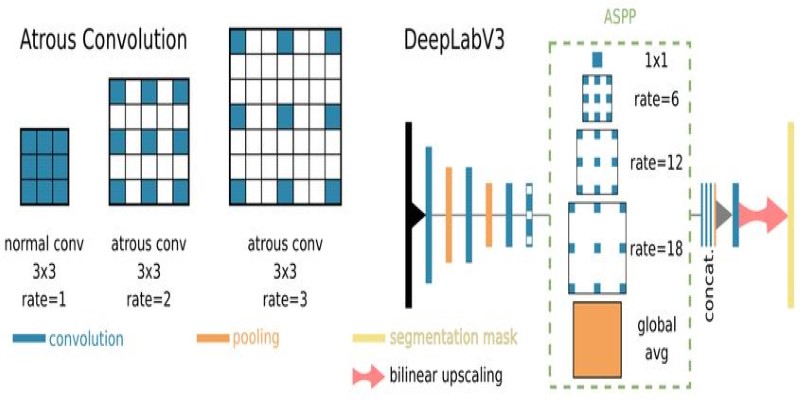
This spread-out kernel lets the network capture wider patterns without pooling or downsampling. The output keeps the same size as the input, which is great for tasks where spatial accuracy matters.
You’ll often see atrous convolution used in fully convolutional networks (FCNs), especially in models like DeepLab. These models need to label every pixel in an image. Instead of compressing and later upsampling the feature map, they keep its size the same and just extend the receptive field using dilation. DeepLab even combines multiple atrous convolutions with different rates. This is known as atrous spatial pyramid pooling (ASPP), which helps the model understand objects at various scales in the same image.
The result is better segmentation accuracy without the usual complexity of deep or high-resolution networks. Atrous convolution handles both local detail and global context in fewer steps.
The most common use of atrous convolution is semantic segmentation, where models label every pixel in an image. This technique helps keep predictions sharp by avoiding heavy downsampling, but it's also useful in other areas.
In medical imaging, for example, you might be identifying tumors in a scan. Details matter; you can't afford to lose them through aggressive pooling. Atrous convolution keeps the original resolution, making small features easier to catch.
In audio processing, it’s been used in models like WaveNet. Here, the model is looking at a waveform instead of an image. Atrous convolution lets it analyze patterns across long-time sequences, which is hard with standard filters. Using dilated filters makes learning short- and long-term patterns in the data easier.
One of its strengths is that it reduces the need for upsampling. Many segmentation models shrink the input image and try to grow it back using interpolation. This often leads to blurry outputs. Atrous convolution avoids that by working directly on high-resolution data.
But there are some trade-offs. Atrous convolution can cause a gridding effect if dilation rates are poorly chosen. This happens when the receptive fields skip over parts of the input too often, creating uneven coverage. Mixing dilation rates or adding regular convolutions in between can reduce this effect.
Another downside is that while the number of parameters stays the same, the memory footprint can increase due to larger effective filter areas. So, even though computation is more efficient than big filters, it's still something to watch for on limited hardware.
Most deep learning libraries make atrous convolution easy to use. In TensorFlow or Keras, you can set the dilation_rate parameter in Conv2D. In PyTorch, the dilation argument in Conv2d does the same thing.

If you're designing a segmentation model, try replacing regular convolutions with atrous ones. Start with low dilation rates in shallow layers and increase them in deeper layers. This gives the model a broader context over time without shrinking the image.
For more complex scenarios, like ASPP, several atrous convolutions are run in parallel using different dilation rates. This helps the model process information at multiple scales. Small dilation rates catch fine details, while larger ones add more context.
You won't need to change your training setup. The optimizer, loss functions, and data pipeline stay the same. What changes is how the model "sees" the input. If your predictions show grid-like patterns or inconsistencies, adjust the dilation settings or reintroduce some standard convolutions to balance it out.
Tuning matters. Not every dataset or task will benefit equally. However, for image labeling or time-based data, where precision and wide context are needed, atrous convolution often delivers better accuracy with less overhead than alternatives like large filters or recurrent layers.
Atrous convolution helps convolutional neural networks cover more ground without extra computation. It lets models see a wider input field while preserving detail—key for tasks like segmentation and medical imaging. Rather than shrinking and regrowing the image, the model keeps the data's size and learns to read it better. With simple tweaks like setting a dilation rate, CNNs become more efficient and accurate for detailed tasks. It's a small change in design that often makes a big difference in output.
Advertisement

How Fireworks.ai changes AI deployment with faster and simpler model hosting. Now available on the Hub, it helps developers scale large language models effortlessly

How the apt-get command in Linux works with real examples. This guide covers syntax, common commands, and best practices using the Linux package manager

Anthropic secures $3.5 billion in funding to compete in AI with Claude, challenging OpenAI and Google in enterprise AI

Think Bash loops are hard? Learn how the simple for loop can help you rename files, monitor servers, or automate routine tasks—all without complex scripting

How to use the ternary operator in Python with 10 practical examples. Improve your code with clean, one-line Python conditional expressions that are simple and effective

Getting the ChatGPT error in body stream message? Learn what causes it and how to fix it with 7 practical ChatGPT troubleshooting methods that actually work

Microsoft’s new AI model Muse revolutionizes video game creation by generating gameplay and visuals, empowering developers like never before

Discover three new serverless inference providers—Hyperbolic, Nebius AI Studio, and Novita—each offering flexible, efficient, and scalable serverless AI deployment options tailored for modern machine learning workflows

Multimodal models combine text, images, and audio into a shared representation, enabling AI to understand complex tasks like image captioning and alignment with more accuracy and flexibility

Learn how to run privacy-preserving inferences using Hugging Face Endpoints to protect sensitive data while still leveraging powerful AI models for real-world applications

Looking for the best way to chat with PDFs? Discover seven smart PDF AI tools that help you ask questions, get quick answers, and save time with long documents

Explore the top 10 large language models on Hugging Face, from LLaMA 2 to Mixtral, built for real-world tasks. Compare performance, size, and use cases across top open-source LLMs